Apuntes
JDBC 🪖
-
JDBC es una API Java, clases e interfaces, que permite a aplicaciones Java acceder a fuentes de datos mediante la ejecución de sentencias SQL. Incluye métodos para:
- Establecer una conexión entre cliente y SGBD
- Ejecutar sentencias SQL
- Recibir los resultados o errores y procesarlos El fabricante debe proporcionar un driver
-
Driver: conjunto de clases que implementan la API JDBC formando adaptadores que:
- Crea y mantiene las conexiones con la BBDD
- Traduce las llamadas a métodos JDBC del cliente en llamadas nativas a la API del DBMS
- Convierte tipos SQL en clases Java y viceversa, los envía al cliente o al SGBD
- Convierte las condiciones de error en excepciones Los drivers se cargan y utilizan en tiempo de ejecución en el lado del cliente
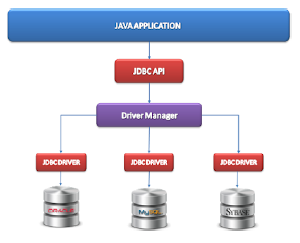
Características JDBC
- Independencia de la base de datos: el cliente es independiente de los detalles de trabajar con una BBDD u otra
- Mapeo objeto-relacional: virtualización de una BBDD orientada a objetos sobre la relacional
Arquitectura JDBC
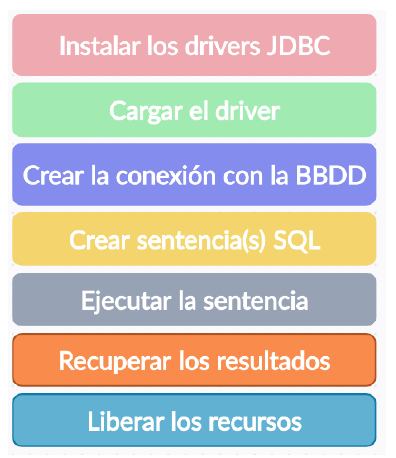
Proceso de desarrollo
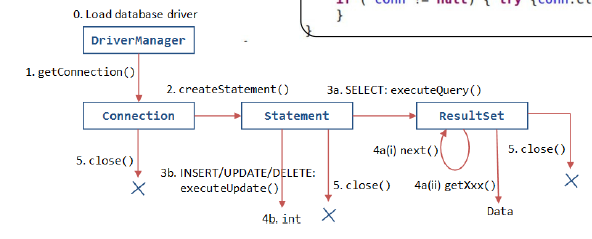
- Para soliccitar la conexión a la BBDD se usa el Driver Manager:
Connection c = DriverManager.getConnection(url, user, pass);-
DriverManager itera a través de los drivers registrados y les pide la conexión. Si el driver no es compatible con el protocolo, devolverá null, sino crea la conexión y devuelve un objeto
java.sql.Connection -
ResultSet: es un proxy que virtualmente contiene filas y columnas y ofrece métodos para recuperarlos y procesarlos
ResultSet rs = st.executeQuery(query);Métodos para leer los datos
getXXX(String field);
getXXX(int columnnField);
previous(); //navega a la fila anterior
first(); //navega hasta la primera fila
last(); //navega hasta la última fila
beforeFirst(); //si después ejecutamos next, devuelve la primera fila
afterLast(); //si después ejecutamos previous devuelve la última fila
relative(int numOfRows); //navega hacia delante o atrás unas filas desde el cursor
absolute(int rowNumber); //navega a la fila indicada- Es importante liberar los recursos en memoria usando el método close() (Connection, Statement y ResultSet)
- No hay que dejar que el ususario final vea los errores de la BBDD
Esquema del proceso de desarrollo
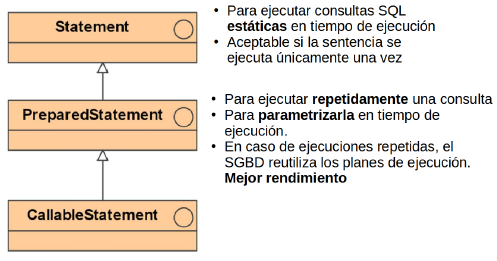
Interfaz Statement
- Statement:
- Para ejecutar consultas SQL estáticas en tiempo de ejecución
- Aceptable si la sentencia se ejecuta únicamente una vez
- Sentencia completamente construida antes de ejecutarla
- Útil principalmente para sentencias DDL CREATE, ALTER, DROP, …
- Rendimiento pobre
- PreparedStatement:
- Para ejecutar repetidamente una consulta
- Para parametrizarla en tiempo de ejecución
- Mejor rendimiento
- Mayor seguridad contra inyecciones SQL
- CallableStatement
Tipos de ResultSet
- ResultSet Type: establece la navegabilidad, posicionamiento y sensibilidad del ResultSet
- ResultSet concurrency: determina si el objeto ResultSet es read-only o puede ser modificado
Type
- Type-forward-only: sin scroll, sin posicionamiento, insensible a cambios en la BBDD
- Type-scroll-insensitive: scroll, posicionamiento, insensible a cambios en la BBDD (a menos que se ejecute nuevamente la consulta)
- Type-scroll-sensitive: scroll, posicionamiento, sensible a cambios en la BBDD
Concurrency
- Concur_read_only: el ResultSet no puede ser actualizado
- Concur_updatable: el ResultSet puede ser actualizado
¿Puede un objeto ResultSet ver los cambios realizados al propio ResultSet?

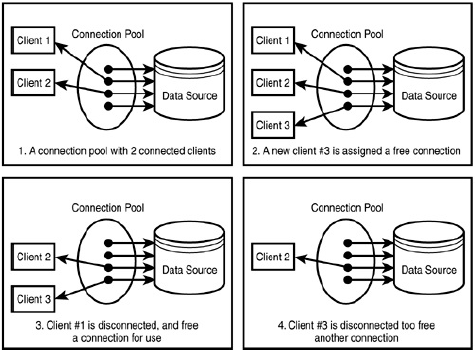
Pool de conexiones
- Es una caché de objetos Connection cuyo objetivo es reducir la sobrecarga derivada de conectarse a la base de datos. Son reutilizables.
Transacciones
-
Una transacción es una secuencia de una o más operaciones (lectura/escritura) que refleja una única operación en el mundo real

-
Por defecto cada sentencia SQL individual se ejecuta de forma transaccional (AutoCommit = true)
-
Una transacción finaliza cuando:
- termina la conexión actual
- Commit implícito o explícito
- Rollback que hace que se cancele
Propiedades de las transacciones (ACID)
- Atomicity: las instrucciones agrupadas en una transacción son atómicas (o todas o ninguna)
- Consistency: cualquier transacción debe conducir la BBDD de un estado consistente a otro estado consistente. Durante se adminten temporalmente datos inconsistentes, pero al finalizar sólo datos consistentes que cumplan las restricciones (clasves primarias, valores negativos…)
- Isolation: aunque varias transacciones se ejecuten concurrentemente, el efecto final debe ser el mismo que si cada transacción se ejecutase una tras otra. Las transacciones han de ser ejecutadas completamente o que el SGBD maneje los detalles de intercalar varias transacciones
- Durability: una vez que la transacción ha sido confirmada (commited), sus efectos deben ser permanentes, incluso si después falla el sistema
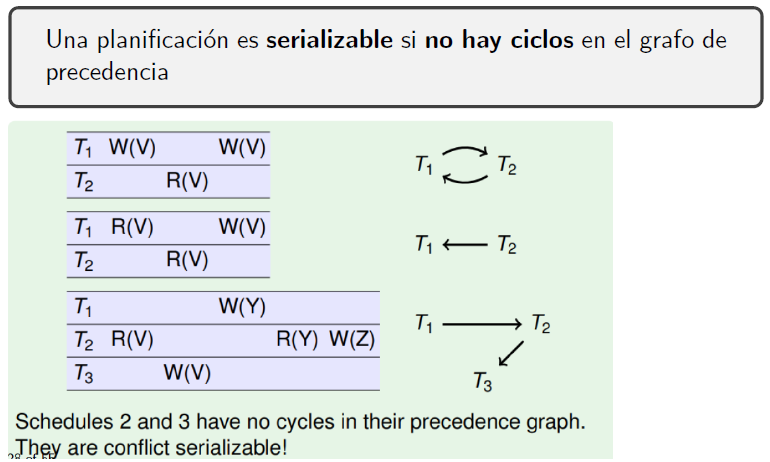
Concurrencia, Planificación y Serialización

- Planificación: intercalado de operaciones de un conjunto de transacciones. El planificador decide el plan de ejecución (planificación). Hay dos tipos:

- Serie: las operaciones no se intercalan, se ejecutan una tras otra

- Serializable: su efecto en la BBDD es el mismo que alguna planificación serie
- Serie: las operaciones no se intercalan, se ejecutan una tras otra
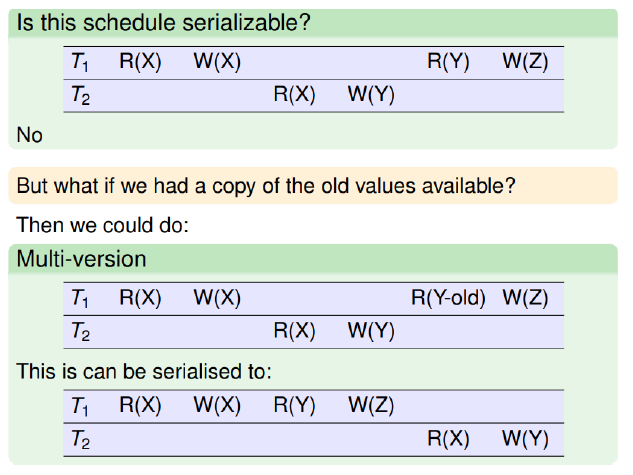
Comprobar si una planificación es serializable

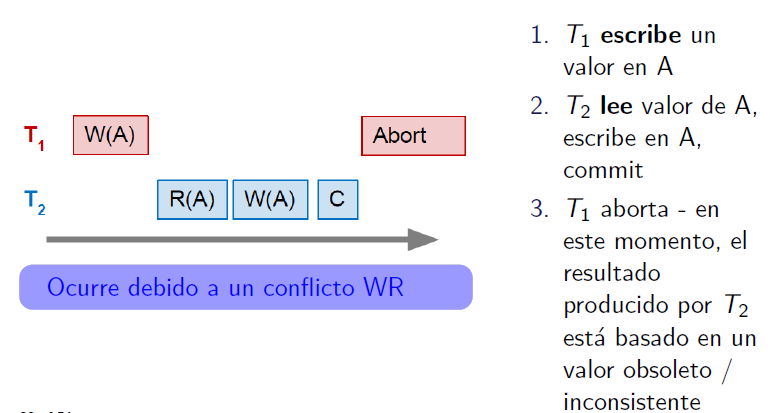
Dirty read / Lectura sucia
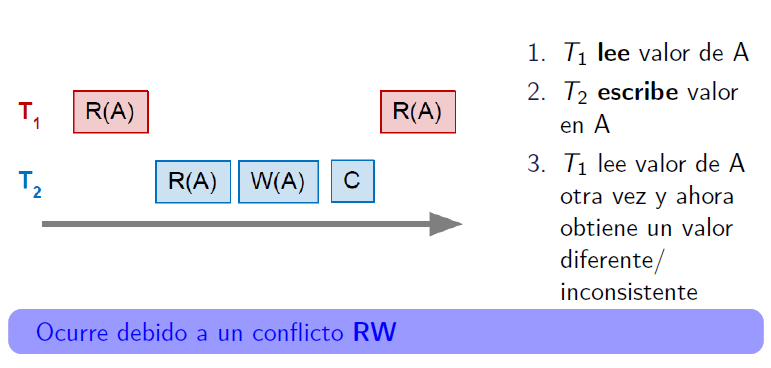
Unrepeatable read / Lectura no repetible
Phantom read / Lectura fantasma

Inconsistent read / Lectura inconsistente
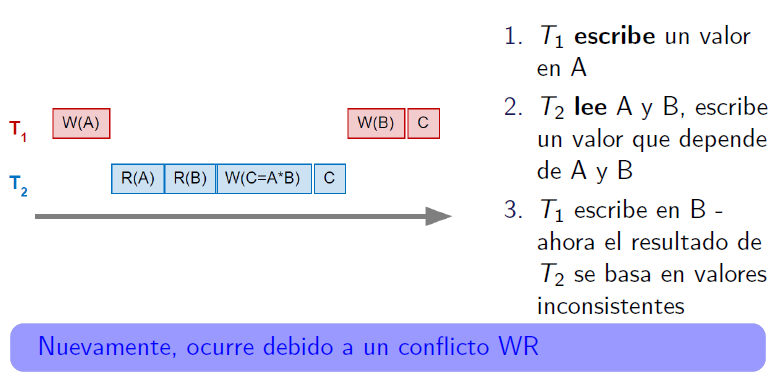
¿Cómo gestionar los conflictos?
- Han de evitarse empleando un mecanismo de bloqueo, pesimista o Lock-based Concurrency Control
- Cada lectura requiere un bloqueo compartido (shared lock)
- Cada escritura requiere un bloqueo exclusivo (exclusive lock)
- El bloqueo genera competencia por los recursos
Control de concurrencia basado en versiones
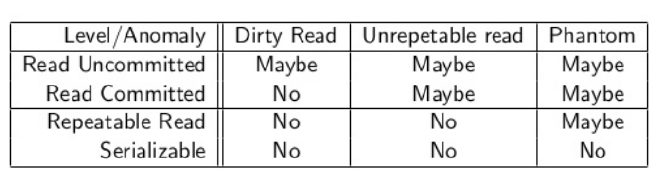
Niveles de aislamiento
- Lectura no confirmada (Read Uncommited)
- Read committed
- Repeatable read
- Serializable
Anomalías vs Niveles de aislamiento
Atributos de calidad para el software
- Escalabilidad: a medida que el sistema crece, qué alternativas razonables existen de lidiar con ese crecimiento
- Mantenibilidad: costes relativos a la reparación o actualización a lo largo de su vida útil
- Reusabilidad: capacidad del softwar de ser reusado en otras aplicaciones
- Extensibilidad: facilidad de adaptar el software a los cambios sin modificar lo que ya existe
Patrones
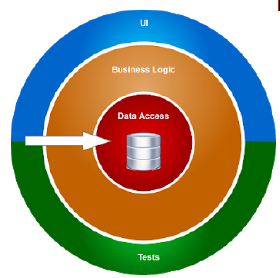
1. Separación en capas
- Secuencia ordenada de capas donde cada capa ofrece servicios que pueden ser usados por componentes que residen en la capa superior
- Cada capa expone a la capa superior una interfaz simple para usar un sistema potencialmente complejo
- Cada capa llama a métodos de la API de la capa inferior
- La capa de presentación se ocupa del cliente
- La capa de negocio implementa las reglas del problema
- La capa de acceso a datos interactúa con los datos persistentes
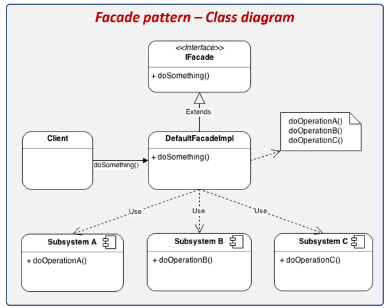
2. Fachada / Façade
- Proporciona una interfaz sencilla (pero limitada) a un conjunto de objetos existentes (sistema complejo)
- Los clientes interactúan con el subsistema a través de la fachada pero ésto no impide el acceso a las clases del subsistema
- Podría haber más de una interfaz para el mismo subsistema
- Oculta los detalles detrás de la interfaz
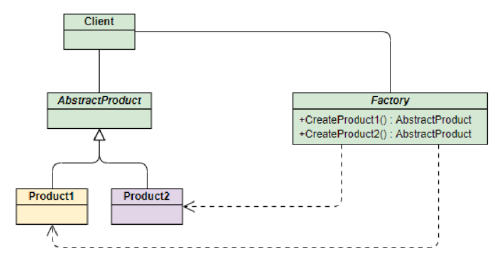
3. Factoría simple / Class Factory
- Una clase Simple Factory es una clase que crea objetos sin mostrar al cliente la lógica de creación de instancias
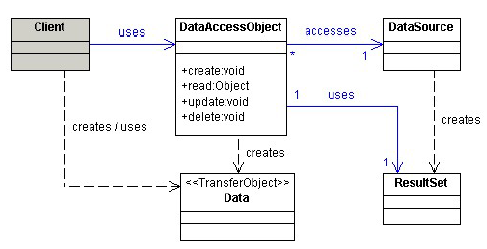
4. Patrón DAO (Data Access Object)
- Permite aislar la lógica de negocio de la persistencia interponiendo un interfaz abstracta. Esto permite que ambas capas evolucionen por separado sin saber nada una de la otra
- Proporciona métodos CRUD: inserción, actualización, borrado y consulta de información
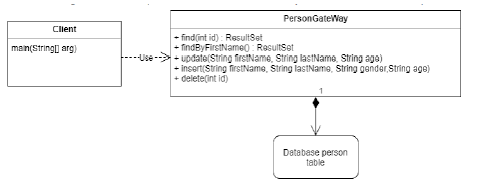
5. Row Data Gateway
- Actúa como un gateway de un único registro en una fuente de datos
- Representa exactamente una única fila devuelta por una consulta
- Cada columna de la tabla es un campo del objeto
- No tiene lógica de dominio
6. Table Data Gateway (TDG)
- Encapsula los datos de una tabla o vista de una base de datos
- Un gateway para cada tabla
- Con una única instancia se gestiona el acceso a todas las filas de una tabla
- Getters retornan colecciones de DTO
7. Service Layer
- Define los límites de una aplicación con una capa de servicios que establece el conjunto de operaciones disponibles y coordina la respuesta de la aplicación en cada operación
- Controla las transacciones
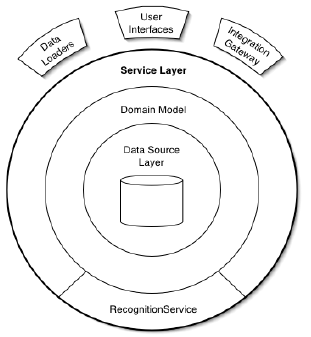
8. Transaction script
- Organiza la lógica de negocio por procedimientos donde cada procedimiento implementa una sóla solicitud de la capa de presentación
- Usa TDGs
- Usa DTOs
9. Command
- Convierte una solicitud en un objeto independiente que contiene toda la información sobre la solicitud
JPA 🦜
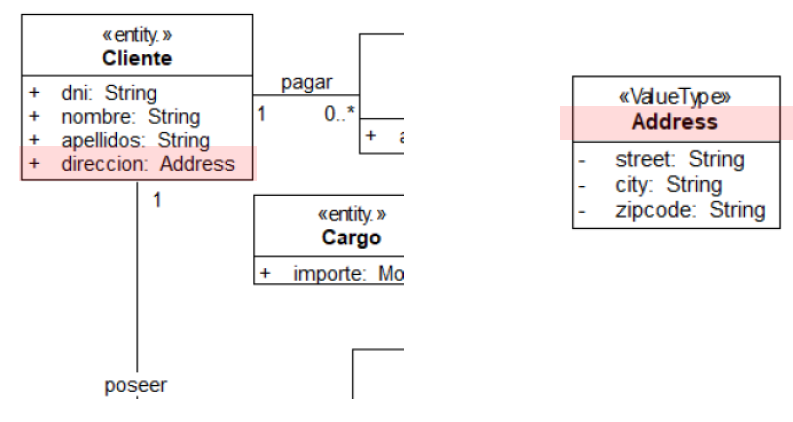
Entidades y Value Types
- Entidades: tienen identidad propia, evolucionan a lo largo del tiempo y participan en asociaciones
- Value Types: no se necesita conocer su identidad, sólo su valor (String, Date, Time, Integer…). Son atributos de entidades y su ciclo de vida está ligado al de la clase
Identidad
- En Java:
- Identidad (a == b), dos referencias apuntan al mismo objeto
- Equivalencia (a.equals(b)), dos objetos representan la misma cosa
- En BDD relacional:
- La clave primaria define la identidad (no hay dos filas con la misma clave)
Hay 3 identidades:

¿Cómo vincular la identidad de la entidad con la identidad Java y la clave primaria?
A través de equals() y hashCode()
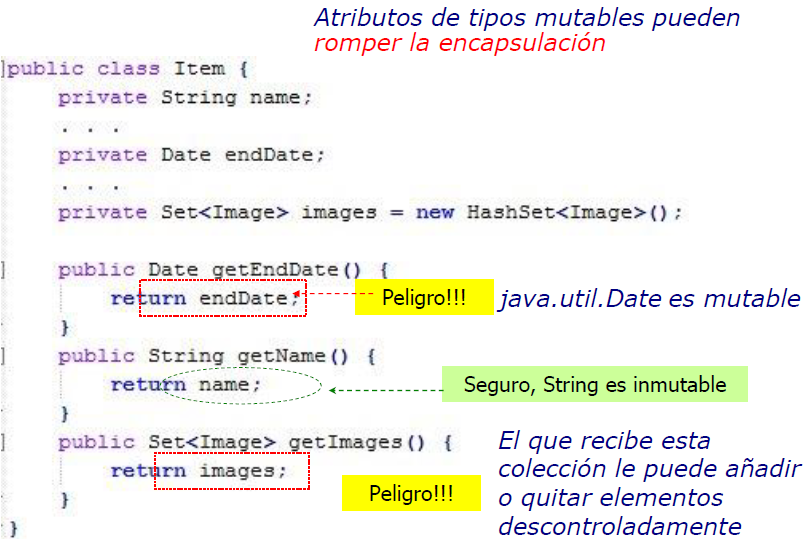
Encapsulación
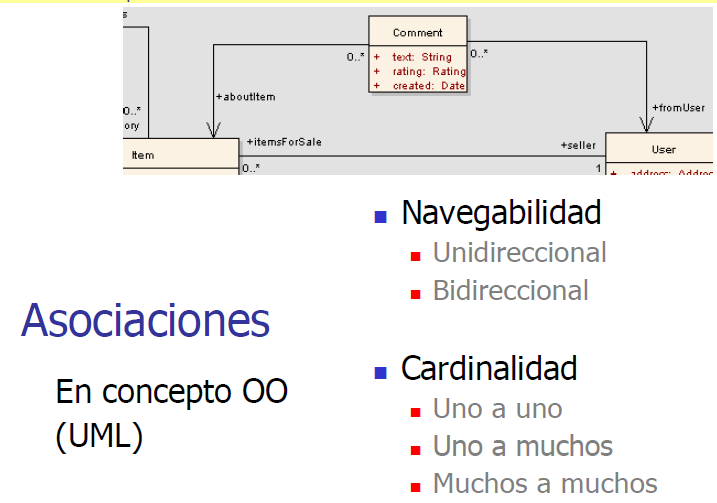
Asociaciones
Concurrencia
Para controlar las transacciones ACID se usa una única caché por hilo y la BDD gestiona las transacciones
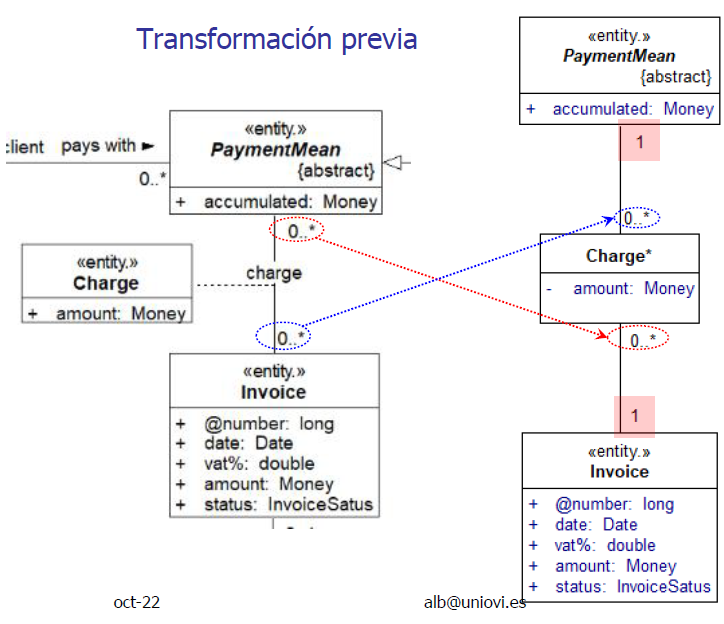
Implementación de asociaciones
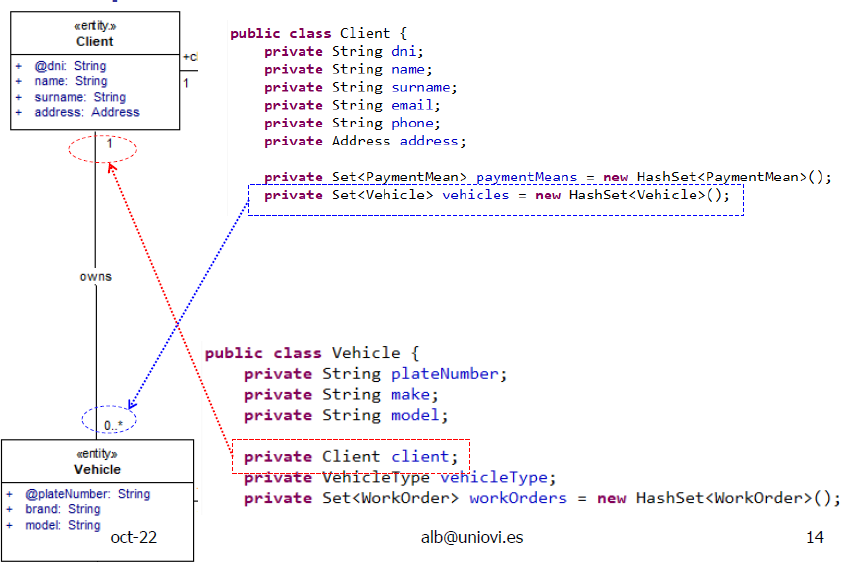
- Las cardinalidades UNO o sin especificar se interpretan como un único elemento:
private Factura factura;- Las cardinalidades MUCHO se representan con un 0..* o 1..*
private Set<Averia> averias = new HashSet<Averia>();-
Es fundamental mantener las referencias cruzadas (link y unlink)


-
Dos getters para el mismo atributo (el público y el de paquete)
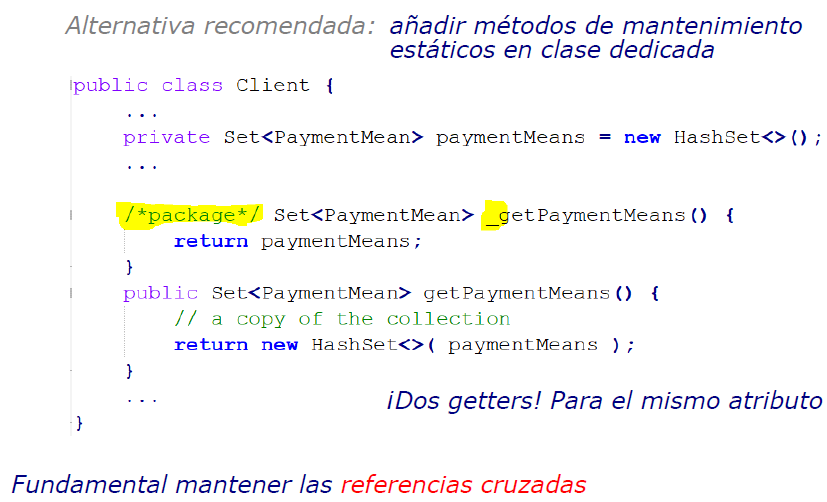
-
Setter restringido

Entidades
- Representa la existencia de algo en el dominio que es de interés y que tiene identidad propia
- Sus propiedades pueden cambiar a lo largo del tiempo, pero sigue siendo “ella”
- Puede estar asociada con otras entidades
- Su ciclo de vida es independiente de otras entidades
- Representamos su identidad basándonos en algún rasgo o característica (atributo(s)). Los atributos que forman identidad son inmutables. Existen dos tipos de identidad:
- Identidad natural:
- Basada en atributos naturales del dominio
- Siempre debe existir atributo o combinación que formen identidad natural
- Identidad artificial:
- Basada en atributo extra (artificial) con valor generado sin repetición posible
- Identidad natural:
private String id = UUID.randomUUID().toString(); //identidad artificial
private String dni; //identidad naturalValue Type
- Son conceptos del dominio (nombre, email, apellidos…)
- Representan un valor, no tienen identidad (su valor es inalterable)
- Son atributos de una entidad (dependen de la entidad de la que forman parte)
- Son inmutables (no tienen setters), como los tipos básicos de Java: Integer, Double, String…
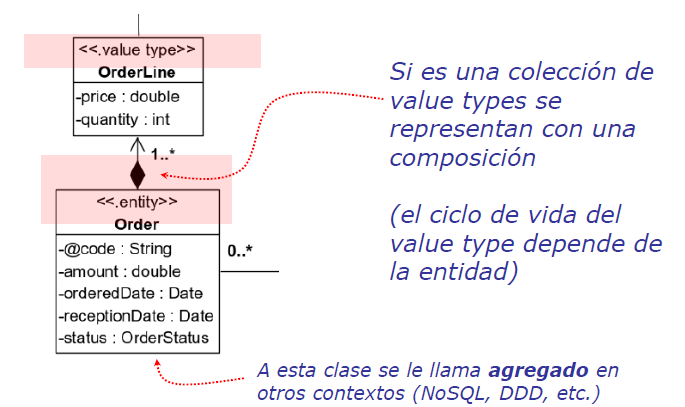
Clases asociativas
- Representan a la vez clase y asociación
- Permiten añadir atributos y funcionalidad a una asociación
- Cada instancia representa un enlace
- Identidad compuesta por los dos extremos → dos objetos sólo pueden estar enlazados una vez
equals() y hashCode()
- Entidades:
- Sólo son redefinidos sobre los atributos que determinan la identidad (Si se opta por identidad artificial va sobre ese atributo)
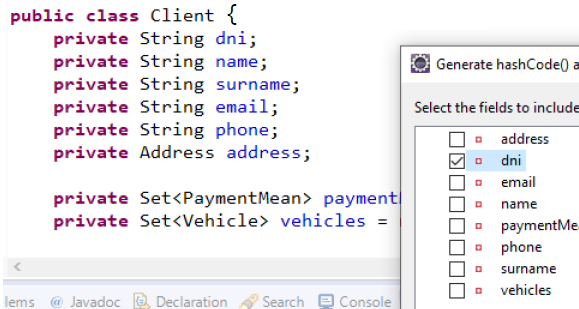
- Sólo son redefinidos sobre los atributos que determinan la identidad (Si se opta por identidad artificial va sobre ese atributo)
- Value Types:
- Son redefinidos sobre TODOS los atributos
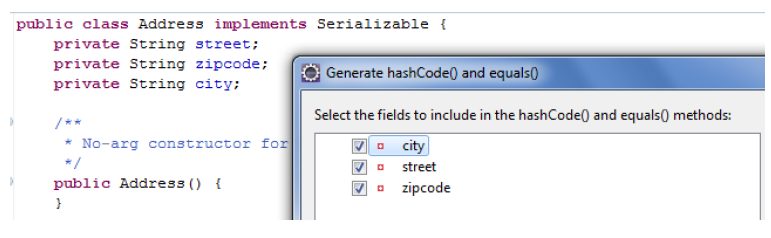
- Son redefinidos sobre TODOS los atributos
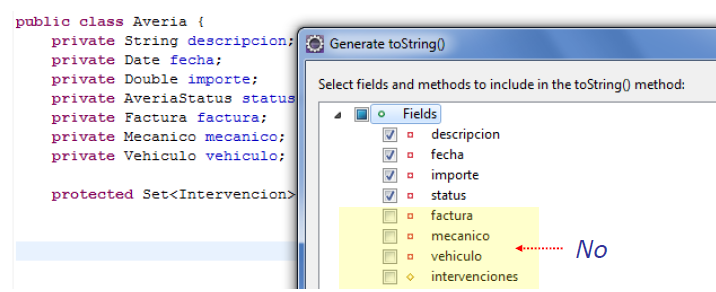
toString()
- Es útil para la depuración
- No incluir referencias a otras entidades
Ciclo de vida de un objeto persistente
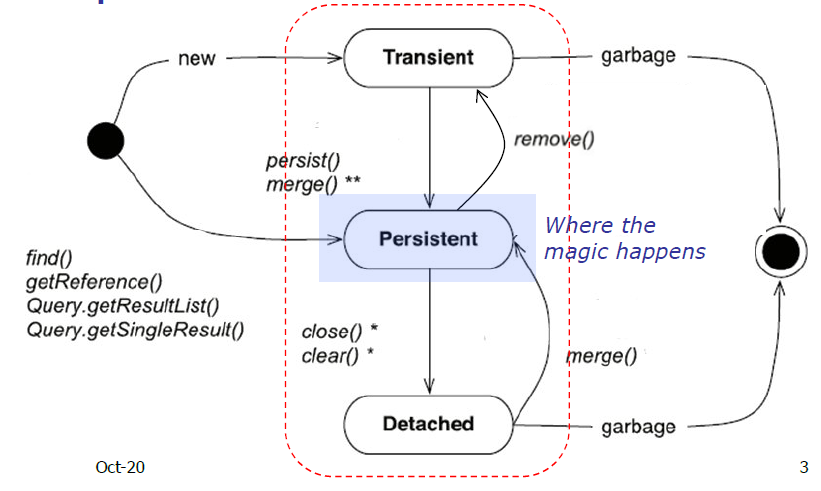
Estados de persistencia
- Transient: objeto recién creado que no ha sido enlazado con el gestor de persistencia (sólo existe en la memoria)
- Persistent: un objeto enlazado con la sesión en el que todos los cambios que se le hagan serán persistentes
- Detached: un objeto persistente que sigue en memoria después de que termina la sesión (existe en java y en la BDD)
Control del ciclo de vida
-
Se gestiona desde un EntityManager (sesión)
-
Un objeto “está en sesión” cuando está en Persistent
-
La sesión es una caché de primer nivel que:
- Garantiza la identidad java y la identidad en BDD
- Se optimiza el SQL para minimizar tráfico a la BDD


-
La identidad sólo está garantizada dentro del contexto:

Escenarios de mapeo
- Green Field:
- El proyecto empieza de nuevo
- El diseño no está condicionado por nada anterior
- El mapeador genera la base de datos a su medida
- Legacy:
- Actualizamos o expandimos un sistema ya existente
- La base de datos ya existe de antes
- El mapeador se debe adaptar al diseño de una BDD ya existente y seguramente retorcido
Condiciones de una clase para ser mapeada
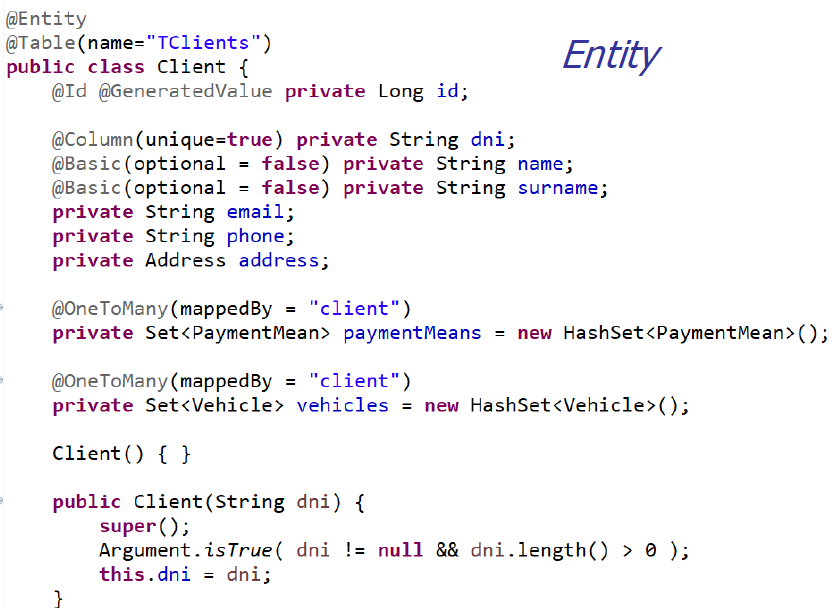
- Clases Java planas (POJO)
- Constructor sin parámetros
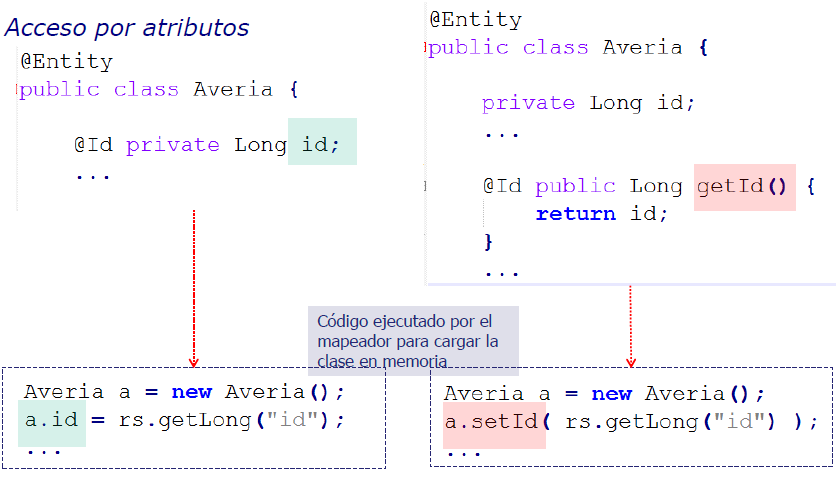
- La información necesaria para persistencia se añade en forma de metadatos (@Anotations, xml)

Posición de @Id
Metadatos en anotaciones y XML
Categorías de anotaciones
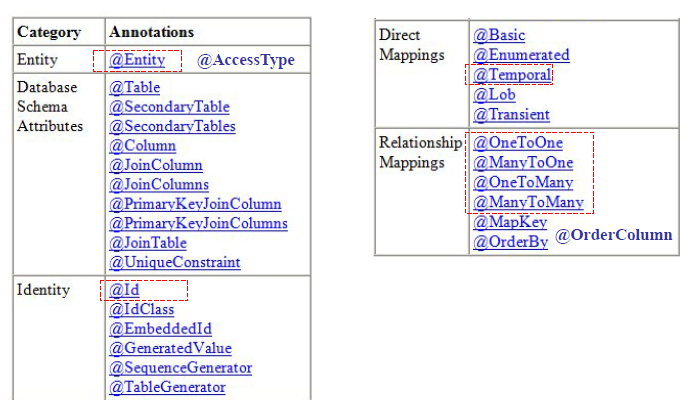
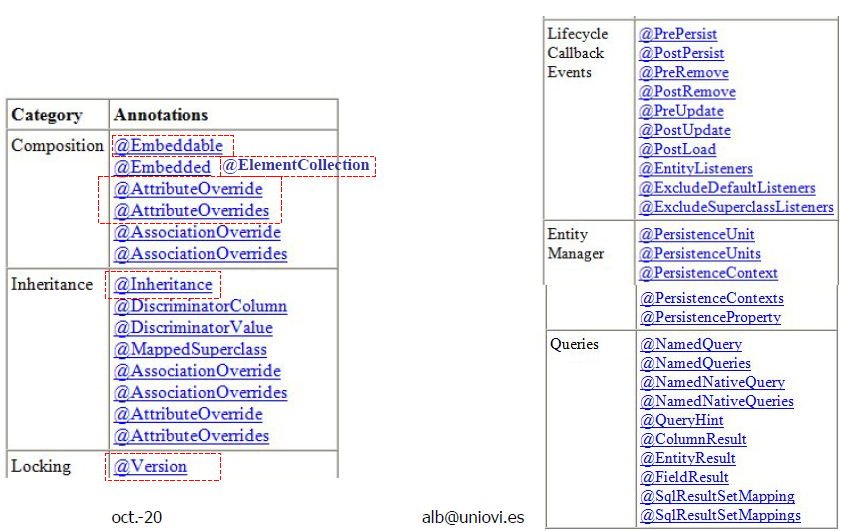
Entidades
- Una entidad se mapea siempre a una tabla
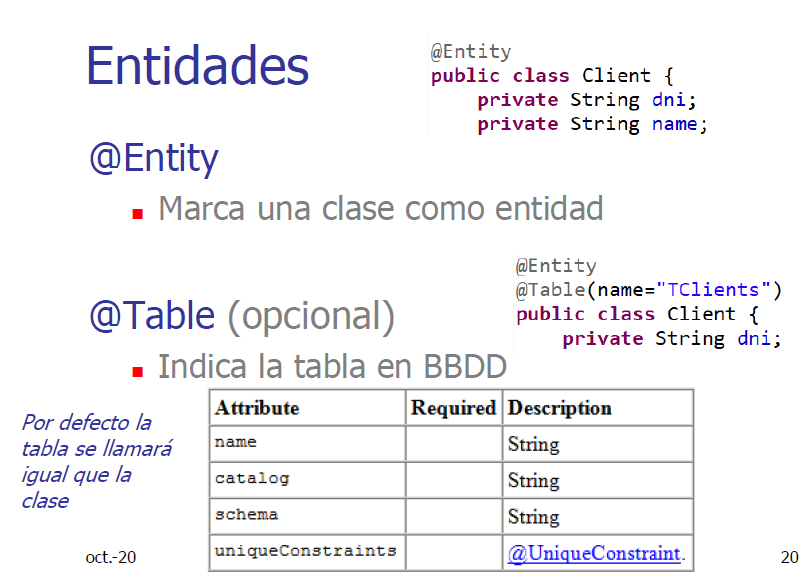
Value Types
- Representan conceptos adicionales del dominio
- Su ciclo de vida depende de la entidad que los posee
- Semántica de composición

@Embeddable marca una clase como ValueType
Identity vs Equality
- Java identity a == b
- Object Equality a.equals(b)
- Database identity a.getId().equals(b.getId())
- Sobre la clave primaria de la tabla
- Se mapean con la etiqueta @Id
- Todas las clases Entidad deben tener @Id (identificador)
No siempre serán iguales las tres identidades. El período de tiempo que sí lo son se le denomina "Ámbito de identidad garantizada" o "Ámbito de persistencia"
Tipos de claves
- Candidata: campo(s) que permiten determinar de forma única una fila
- Natural: candidatas con significado para el usuario. Las entiende y las maneja día a día
- Artificial (subrogada): sin significado en el dominio, pero sí en el sistema. Son siempre generadas por el sistema
Problema con las claves naturales…
¿Siempre son NOT-NULL? ¿Nunca van a cambiar? ¿Nunca se van a repetir?
Estrategia recomendable
- Usar siempre claves artificiales como claves primarias (un Long o un String eficiente)
Asociaciones en el mapeador
@OnetoOne (mappedBy = "name")
@OnetoMany (mappedBy = "name")
@ManytoOne (mappedBy = "name")
@ManyToMany (mappedBy = "name")Estrategias para mapear la herencia
- Tabla única para toda la jerarquía:
InheritanceType.SINGLE_TABLE- Todas las tablas persisten en una única tabla con la unión de todas las columnas de todas las clases
- Usa un discriminador en cada fila para distinguir el tipo
- Todas las columnas no comunes deben ser nulables
- Van a quedar columnas vacías
- Puede generar tablas que ocupan mucho con pocos datos
- Tabla por cada clase no abstracta:
InheritanceType.TABLE_PER_CLASS- Una tabla por cada clase no abstracta
- Las propiedades heredadas se repiten en cada tabla
- Evita los nulos
- Consultas menos eficientes
- Cambios en la superclase se propagan a todas las tablas
- Tabla por cada clase:
InheritanceType.JOINED- Cada clase de la jerarquía tiene su propia tabla
- Las relaciones de herencia se resuelven con FK
- Cada tabla sólo tiene columnas para las propiedades no heredadas
- Las consultas son más complicadas
- Para jerarquías complejas el rendimiento puede ser peor
Consultas en JPQL


-
getSingleResult() sólo puede ser invocado para aquellas consultas en las que está garantizado que siempre van a devolver un único resultado. Si se usa cuando puede devolver más de un elemento, null u Optional.empty() saltará una excepción

-
Hay que usar siempre alias
select u from User u where u.firstname like 'G%'
select u from User u where u.firstname not like 'G%'
select u from User u where u.firstname like '\G%' escape='\'Funciones NOSQL


¿Cómo hacer buenas consultas?
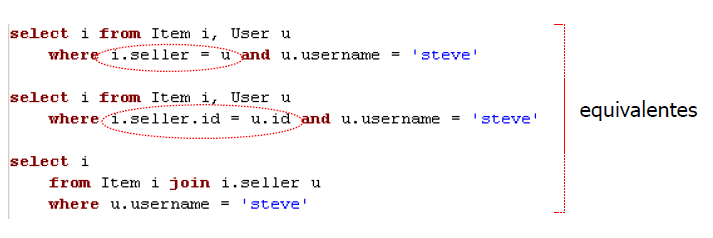
Agrupamiento
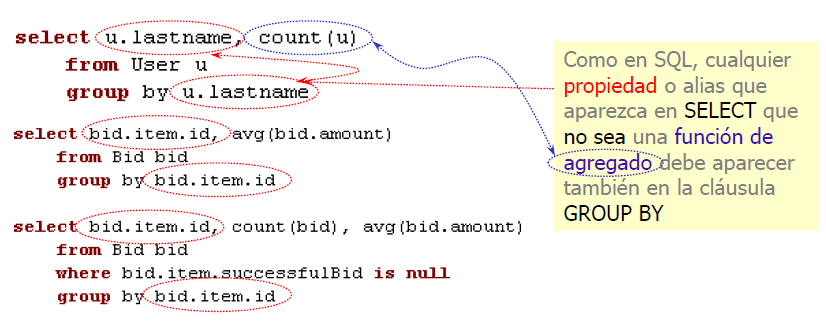

Varios SELECT
- En JPQL los subselects sólo pueden ir dentro del WHERE
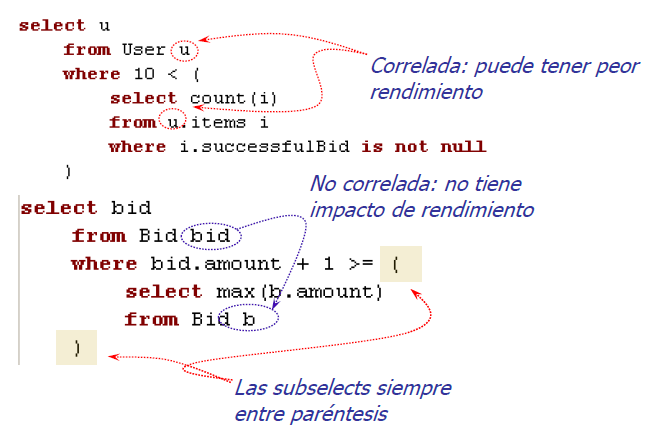
Any, all, some, in

Repositorios
- Almacén de objetos con interfaz de tipo colección (add, remove…, sin update)
- Las implementaciones de repositorios resuelven métodos de consulta usando el mapeador
- Un repositorio por cada entidad
Recuperación de información 🧋
- La recuperación de información se ocupa de la representación de documentos y consultas, del matching entre documentos y consultas, de la ordenación de los resultados y de la evaluación del rendimiento de sistemas concretos en relación con las espectativas de los usuarios
Definiciones básicas
- La ==recuperación de información== (RI) consiste en el estudio y desarrollo de sistemas automatizados que permitan a una persona usuaria determinar si existen (o no) documentos textuales relacionados con una necesidad de información determinada (que se formula normalmente con una consulta textual). Dichos documentos deben ser relevantes para la necesidad de esa persona y normalmente el sistemalos retorna ordenados.
- Un ==documento== es la unidad de trabajo fundamental en un sistema RI, es decir, es el elemento más simple que se puede retornar como un resultado único.
- Un documento es un fragmento de texto libre expresado en algún lenguaje natural, usando algún sistema de escritura
- El contenido puede ser de cualquier tipo y de extensión arbitraria
- Los sistemas RI pueden explotar la estructura de los documentos
- Una colección es un conjunto de documentos con el que las personas usuarias esperan satisfacer sus necesidades de información
- En la ==búsqueda ad hoc== la persona usuaria tiene en mente una necesidad específica y formula para la misma una consulta personalizada que envía al sistema de recuperación de información para que éste pueda buscar en una colección de documentos, seleccionar algunos y ordenarlos según su relevancia para la consulta recibida
- Una necesidad de información es la expresión de un objetivo informativo concreto que tiene una persona usuaria. Las necesidades se pueden expresar en lenguaje natural, con imágenes o con una serie depalabras clave
- Una consulta es una expresión escrita en algún lenguaje de entrada de un sistema RI que la persona usuaria contruye para formular su necesidad de información de tal modo que el sistema sea capaz de recuperar el mayor número posible de resultados relevantes. La mayoría de los sistemas RI aceptan consultas formadas por palabras clave conectadas por operadores booleanos
Modelo conceptual de RI
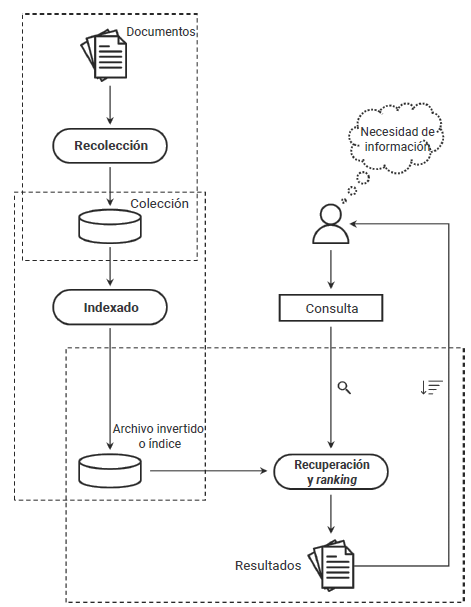
-
Los documentos de texto en bruto no se utilizan directamente para la recuperación y ranking, es necesario transformarlos durante el proceso de indexado. Cuando esto se lleva a cabo, hay una serie de decisiones que tomar:
- El vocabulario a usar
- Las características del texto que hay que preservar/eliminar
- Explotar (o no) la estructura de los documentos
-
Hapax legomenon: palabra que aparece una única vez en un contexto
RI vs SGBD
Difieren en:
-
Los elementos que almacenan
-
Las consultas que aceptan
-
La forma en la que hacen el matching entre elementos y consultas
-
Los resultados que retornan
-
Los SGBD almacenan datos muy estructurados con distintos campos con una semántica bien definida
-
Los sistemas RI almacenan textos escritos en lenguaje natural con poca o ninguna estructura y cuya semántica es totalmente ajena al sistema
-
Las consultas en los SGBD se formulan en lenguajes artificiales y deben estar completamente definidas para funcionar
-
Los sistemas RI aceptan consultas en texto libre. Además, las consultas suelen ser cortas, poco específicas e incompletas.
-
Los SGBD retornan coincidencias exactas
-
Los sistemas RI proporcionan resultados aproximados
-
Los SGBD retornan todos los ítems que hacen match con una conslta concreta y no necesitan estar ordenados
-
Los sistemas RI retornan resultados ordenados puesto que algunos documentos son más relevantes que otros
Historia de la recuperación de información
-
1940
- se describe un dispositivo que permitiría a los usuarios almacenar, enlazar y encontrar información, el ==memex==
-
1950
- se introduce el término ==recuperación de información==
- primera descripción de un sistema RI automático. Uso de frecuencia de términos para determinar su relevancia y uso de listas de palabras vacías
- primera propuesta de un sistema de resumen automático
-
1960
- primera alternativa aritmética a la búsqueda booleana
- primer intento de evaluación experimental de sistemas RI
- se proponen el modelo vectorial y la similitud del coseno
-
1970
- se propone la ==cluster hypothesis==, según la cual los documentos similares tienden a ser relevantes para las mismas consultas
- se propone el concepto de ==idf (inverse document frequency)==
- primera colección de evaluación moderadamente grande (11500 documentos)
-
1980
- se propone el ==primer algoritmo de stemming==
- se propone la técnica Latent Semantic Indexing
- se inventa la web
- primera propuesta de un método learning to rank
-
1990
- se propone el ==algoritmo de ranking BM25==
- se desarrollan los primeros buscadores web
- desarrollo de sistemas IR robustos usando n-grams
- primeros métodos de pseude-relevance feedback
- primeros pasos hacia la web semántica
- se propone el ranking basado en hiperenlaces
- uso de modelos lingüísticos para RI
-
2000
- Se propone la Web Semántica
- Se propone el relevance model
- Se propone el ==método RM3 de expansión de consultas==
- Se presenta un enfoque basado en aprendizaje profundo para hacer la búsqueda neuronal
-
2010
- primera propuesta para usar word embeddings
- se propone ==word2vec==
-
Preprocesamiento de documentos: consiste en extraer el vocabulario del texto completo aunque se eliminen algunas palabras (palabras vacías) y otras que se aglutinan mediante algoritmos de estematización o lematización
Tokenización
- Es el proceso por el que se divide una secuencia de caracteres en elementos significativos más pequeños (tokens), que se usarán en el indexado.
- Hay casos en los que los tokens pueden separarse o mantenerse juntos: Unión Europea, recuperación de información… Este tipo de secuencias se conocen como términos multipalabra o MWE (multiword expressions)
Eliminación de palabras vacías
- Las ==palabras vacías== son aquellas palabras que, a pesar de su uso frecuente, aportan poco significado a un texto por sí solas
- Durante el procesamiento de documentos también es crucial el método part of speech tagging
Normalización
- Normalización: Se refiere a aquellos procesos que persiguen mejorar el matching entre términos aunque no sean la misma secuencia exacta de caracteres
- Al proceso de pasar a minúsculas todo el texto se le conoce como case-folding
- Muchos idiomas son lenguas flexivas, por lo que existe el número, género y tiempo de los verbos
- Stemming: consiste en truncar las palabras a su raíz léxica o stem, no a su lema
- Ej: universo, universidad, universitario, universitarias
- Es una forma sencilla de aglutinar términos semánticamente relacionados, reducir el tamaño del índice e incrementar la exhaustividad
- Sin embargo, los algoritmos de stemming sufren de overstemming (tendencia a reducir a la misma raíz términos no relacionados)
- El overstemming puede reducir la precisión al recuperar documentos que no tienen nada que ver con la necesidad de información expresada en la consulta. Por ello es preferible usar la lematización
- Lematización: es una herramienta de procesamiento de lenguaje natural. Realiza un análisis morfológico del texto para identificar el lema de cada token
- Un lema es una palabra que encabeza un artículo en un diccionario o enciclopedia
- Mientras que el stemming es una aproximación heurística un tanto cruda, la lematización realmente aglutina todas las formas flexionadas de una palabra en un solo término
Procesamiento del lenguaje natural
- El PLN es un campo interdisciplinar que involucra la lingüística y la informática con el objetivo de hacer que los ordenadores puedan manejar las complejidades de los lenguajes humanos
Índices
-
Stringology: estudio de algoritmos y estructuras de datos para procesar texto, incluyendo la búsqueda de texto. Incluye pattern matching, búsqueda de subcadenas, búsqueda de subcadenas aproximadas, búsqueda de subcadena común más larga entre dos cadenas y archivos invertidos o índices
-
Índice: estructura de datos que evita que las consultas deban compararse con todos los documentos en la colección
-
Inverse document frequency: cuantos menos documentos contienen un token, más importante es ese token. Si un token aparece mucho no es útil, pero si aparece poco sí lo es
Modelos RI
- Para cada modelo hay que especificar
- cómo se representan los documentos
- cómo se representan las consultas
- cuál es la función de ranking
NoSQL 🪀
Características de NoSQL
- Modelo de datos no relacional, basado en agregados
- Esquema flexible (sin esquema - schemaless)
- Orientación a clústers
- Open Source
- Orientación a los problemas de los grandes servicios web
- Son bases de datos menos maduras
- Transacciones de bajo nivel, atomicidad elemental sin transacciones
- Orientado a procesos
Principales modelos de datos NoSQL
- Clave-Valor: Riak, Redis…
- Documental: MongoDB, RavenDB…
- Almacenamiento en columnas: Cassandra, HBase…
- Grafo: Neo4j…
Agregados
- Agregado:
- Conjunto de objetos relacionados tratado como unidad
- Unidad típica para persistencia (almacenamiento), consistencia/atomicidad (transacciones) y distribución
Almacenes Clave-Valor
- Asociación clave-valor
- Recuperación del valor buscando por clave
- Valor es un agregado opaco a la base de datos
- Sin semántica, tipo void
- La aplicación da semántica
Bases de datos documentales
- Sistema clave-valor
- Valor no opaco, documento agregado con estructura (ej: JSON)
- Consulta por clave
- Consulta por contenido del documento
Almacenes en columna
- Estructuras de agragados clave-valor en dos niveles:
- Primer nivel
- Clave de la fila
- Agregado asociado
- Segundo nivel (columnas)
- Clave de columna
- Valor de la columna
- Primer nivel
Bases de datos de grafo
- Estructura de datos de grafo
- Nodos con propiedades
- Relaciones entre nodos (arcos)
- Unidireccionales / Bidireccionales
- Propiedades en relaciones
Distribución de los datos
- Escalabilidad de datos
- Vertical: aumentar la capacidad del servidor
- Horizontal:
- Añadir más servidores → distribución
- Bases de datos en clúster
- Distribución de datos
- Repartirlos entre distintos servidores
- Mayor rendimiento, disponibilidad
- Mayor complejidad
- Alternativas para la distribución
- Servidor único, fragmentación y replicación
Servidor único
- No se distribuyen los datos
- Es la opción más sencilla
- Es la mejor opción SI SE PUEDE, en función de las necesidades de la aplicación
Fragmentación (sharding)
- Consiste en fragmentar los datos y repartirlos entre servidores
- Cada servidor es responsable de un fragmento
- No mejora la robustez
Replicación maestro-esclavo
- Consiste en replicar los datos entre los nodos
- Maestro: es la fuente de referencia (la autoridad)
- Gestiona las actualizaciones
- Retransmite las actualizaciones a los esclavos
- Son definidos manualmente o automáticamente
- Esclavos: repiten los datos
- Mayor escalabilidad y robustez en las lecturas
Replicación entre iguales (peer to peer)
- No hay maestro, todas las réplicas son equivalentes
- Todas pueden aceptar actualizaciones (escrituras)
- Existe una coordinación para sincronizar las actualizaciones
- Tienen mayor robustez que las maestro-esclavo
- Puede haber inconsistencias al hacer escrituras simultáneas
Teorema CAP
- Elementos principales:
- Consistencia
- Respuestas correctas a los clientes
- Disponibilidad
- Si hay acceso, el nodo contesta
- Particionamiento (tolerancia a partición)
- Partición de clúster dividida por fallo de red, sigue respondiendo a los clientes
- Sólo puede haber dos a la vez
- Consistencia
ACID vs BASE
- ACID tradicional
- Atomicidad
- Consistencia
- aIslamiento
- Durabilidad
- BASE NoSQL
- Basically Available
- Soft state
- Eventual Consistency
Quorums
- Quorum de escritura: W > N/2
- Inconsistencia de escritura. Gana la escritura que alzanza la mayoría de nodos
- W: nodos que participan en la escritura
- N: factor de replicación (número de copias del dato)
- Quorum de lectura: R
- Número de nodos a contactar para estar seguro de leer el dato actualizado. Depende del W
- No hay quorum de escritura, así que hay que preguntar a todos porque puede detectarse un conflicto de escritura
Map/Reduce
- Patrón de paralelización de computación en clúster
- Map
- Lee datos de agregado y genera listas clave-valor
- Paralelizable. Ejecutado en el nodo del agregado
- Reduce
- Toman valores pertenecientes a la misma clave y los reducen a un valor único
- Paralelizable por valor de clave
Preguntas 🎅🏻
Preguntas JDBC
- ¿Cuáles son los errores que pueden surgir durante la carga del controlador? ClassNotFoundException
- Errores surgidos durante el acceso a la BBDD: SQLException
- ¿Cómo evitar NULL?
- Evitar usar métodos getXXX()
- Usar clases envoltorio (wrapper) junto con wasNull()
- Usar tipos de datos primitivos junto con wasNull()
- ¿Qué es un driver (JDBC)? Es una implementación de diferentes clases e interfaces Java que abstraen las funciones de acceso a una base de datos para que los programas Java puedan acceder a diferentes SGBD a través de SQL
- Tipos de resultset en función de su navegabilidad e (in)sensibilidad. ¿A través de qué método se establece el tipo de ResultSet a utilizar?
- En función de su navegabilidad e insensibilidad
- En función de su capacidad para actualizar
- CONCUR_READ_ONLY: NO actualizable
- CONCUR_UPDATABLE: SI actualizable
- ==Se establece a partir del método executeQuery()==
- Transacciones y niveles de aislamiento como en prácticas
- ==Una transacción es una secuencia de una o má operaciones (lectura/escritura) que reflejan una sola operación en el mundo real. Características de una transacción (ACID):==
- ==Atomicidad: o se completan o no se completan, nunca quedan a medias==
- ==Consistencia: sólo se guardan datos válidos==
- ==aIslamiento: las transacciones no se afectan las unas a las otras==
- ==Durabilidad: los datos una vez escritos nunca se perderán==
- ==El aislamiento es una propiedad de las transacciones que define cuándo y cómo los cambios producidos por una operación se hacen visibles para las demás operaciones concurrentes. Niveles de aislamiento:==
- Problemas de una transacción concurrente A mayor concurrencia, mayor riesgo de que se produzcan efectos no deseados
- Dado el siguiente esquema, completarlo:

- En el modo de aislamiento Read-Uncommitted puede producirse
- Lectura sucia, lectura fantasma y lectura no repetible
- Ventajas de usar Statement
- Mejor para consultas estáticas en tiempo de ejecución
- Aceptable si la sentencia se ejecuta únicamente una vez
- ¿Qué patrón nos permite acceder a un servicio sin conocer la clase que lo implementa?
- Abstract Factory
- Determina si la siguiente aplicación presenta anomalías y en tal caso qué nivel(es) de aislamiento evitan que se produzcan

- Se produce una lectura no repetible.
- Evitaría que se produjese los niveles de lectura repetible y serializable
Dirty read / Lectura sucia
Unrepeatable read / Lectura no repetible
Phantom read / Lectura fantasma
Inconsistent read / Lectura inconsistente
13. Completa el siguiente esquema
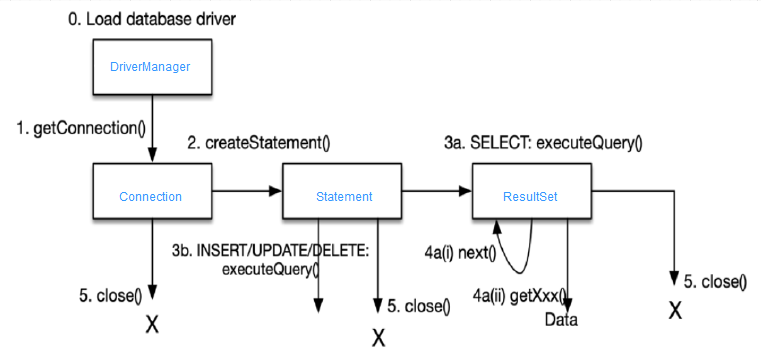 14. Un ResultSet de tipo Scroll Insensitive puede ver:
Actualizaciones internas y eliminaciones internas
15. ¿Cuál de las siguientes afirmaciones sobre el patrón Transaction Script es cierta?
14. Un ResultSet de tipo Scroll Insensitive puede ver:
Actualizaciones internas y eliminaciones internas
15. ¿Cuál de las siguientes afirmaciones sobre el patrón Transaction Script es cierta?
- Es ideal para sistemas con poca lógica
- Modelo procedimental simple y fácil de entender RESP
- Tiene poca sobrecarga de rendimiento
- Funciona bien cuando se combina con Row Data Gateway o Table Data Gateway
- Aumenta la duplicación de código
- No es adecuado cuando el modelo de dominio es complejo
- Completa el siguiente esquema con las operaciones que se realizan
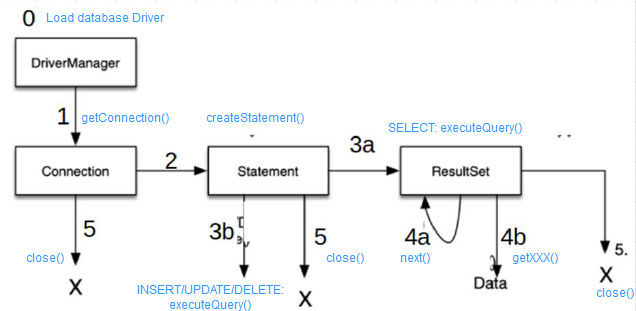
- ¿Qué patrón utilizarías para conectar la interfaz de usuario con los distintos servicios que conforman la aplicación?
- Service Layer
- Una serie de servicios A, B, … cada uno de los cuales pertenece a un dominio distinto, se ejecutan en aplicaciones separadas y ofrecen cada uno APIs independientes, necesitan ser utilizados conjuntamente por parte de un cliente. Elija UNO de los siguientes patrones de diseño para orquestar su aplicación y explique su adaptación al problema. Fachada, Factory, Layering.
- Fachada: proporciona una interfaz simple para un subsistema complejo, se estructuran varios subsistemas en capas, ya que las fachadas serían el punto de entrada a cada nivel
Preguntas JPA
- Entidad y ValueType. ¿Qué es mutable e inmutable en cada uno de ellos? ¿Sobre qué atributos se deben definir los métodos hashCode() y equals() en cada uno de ellos?
- ==Entidad: una entidad representa un concepto del dominio que se puede asociar a otras entidades y tiene un ciclo de vida independiente. Debe tener una identidad (clave primaria en BDD) que es inmutable. Mutables serían todos quellos atributos que se pudiesen modificar en un futuro y rompiesen el encapsulamiento. Los métodos hashCode() y equals() se redefinen sólo sobre los atributos que determinan la identidad.==
- ==ValueType: representa un valor, no tiene identidad. Su valor es inalterable. Se suelen presentar como atributos de una entidad. Su ciclo de vida depende enteramente de la entidad a la que pertenece. Son atributos inmutables (no hay setters). Los métodos hashCode() y equals() se redefinen sobre TODOS los atributos.==
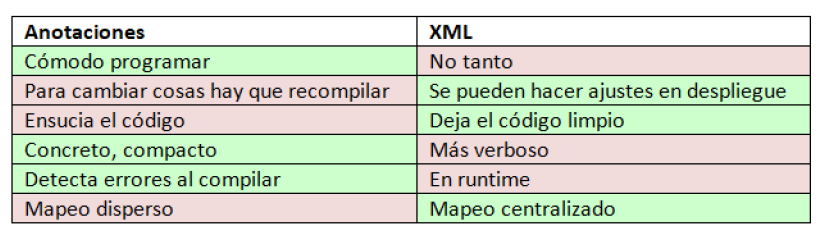
- Diferencias XML y anotaciones
- ¿Cómo se debe usar el atributo @Id?
- El atributo @Id se usa para comprobar si dos entidades de la base de datos son la misma: a.getId().equals(b.getId()) -> Si es true, son la misma entidad. Deberemos poner la notación @Id en el atributo de la entidad que vaya a ser clave en la tabla de la BDD.
- Consulta sobre matrícula alumno y asignatura (todos los alumnos con nota mayor de 5 y matriculados en una asignatura con un código)
select a from Alumno a
where a.mark >= 5 and a.subject.id = ?1- ¿En qué estado están los objetos devueltos por una consulta JPQL?¿y el que devuelve el método find(…)?
- Persistent
- Persistent
Estados de persistencia
- Transient: objeto recién creado que no ha sido enlazado con el gestor de persistencia (sólo existe en la memoria)
- Persistent: un objeto enlazado con la sesión en el que todos los cambios que se le hagan serán persistentes
- Detached: un objeto persistente que sigue en memoria después de que termina la sesión (existe en java y en la BDD)
- Entidad y ValueType. ¿Sobre qué atributos se deben definir los métodos hashCode() y equals() en cada uno de ellos?
- ==Entidad: sobre los atributos que conformen la identidad de la entidad (ya sea natural o artificial)==
- ==ValueType: sobre TODOS los atributos==
- ¿Qué estrategias usan los mapeadores O/R para recrear en memoria una sección del grafo?
- Eager loading: se carga un objeto y sus asociados
- Lazy loading: se carga al necesitarlo
- ¿Por qué no se puede utilizar como identidad de una entidad un atributo con las anotaciones @Id @GeneratedValue?
- No se debe utilizar @GeneratedValue pues la identidad es inestable, ya que no se asigna hasta FLUSH de la base de datos.
- ¿Qué parámetros mínimos debe recibir el constructor de una Entidad? ¿Y el de un ValueType?¿Por qué?
- Ambos deben recibir al menos un parámetro que corresponda a la clave primaria de la Entidad para que se pueda crear la instancia de la entidad.
- ¿Qué fallos encuentras en estas consultas JPQL?
select * from TMechanics m --no se puede usar *
select m from Mechanics m --la tabla se llama TMechanics
select m from mechanic m --la tabla se llama TMechanics
select * from TMechanics --falta asignar alias a TMechanics- Si bajo la arquitectura hexagonal en una clase que representa una entidad del modelo de dominio hay un
import uo.ri.cws.application.service.*;¿qué significa?
- Que se trata de una Factoría de servicios
- Un mapeador de objetos a relacional (O/R) debe resolver las diferencias entre los dos paradigmas. ¿Cómo resuelve un mapeador JPA la herencia?
- ==Tabla única para toda la jerarquía:
InheritanceType.SINGLE_TABLE- ==Todas las tablas persisten en una única tabla con la unión de todas las columnas de todas las clases
- ==Usa un discriminador en cada fila para distinguir el tipo
- ==Todas las columnas no comunes deben ser nulables
- ==Van a quedar columnas vacías
- ==Puede generar tablas que ocupan mucho con pocos datos
- ==Tabla por cada clase no abstracta:
InheritanceType.TABLE_PER_CLASS- ==Una tabla por cada clase no abstracta
- ==Las propiedades heredadas se repiten en cada tabla
- ==Evita los nulos
- ==Consultas menos eficientes
- ==Cambios en la superclase se propagan a todas las tablas
- ==Tabla por cada clase:
InheritanceType.JOINED- ==Cada clase de la jerarquía tiene su propia tabla
- ==Las relaciones de herencia se resuelven con FK
- ==Cada tabla sólo tiene columnas para las propiedades no heredadas
- ==Las consultas son más complicadas
- Para jerarquías complejas el rendimiento puede ser peor
- Añadiendo anotaciones de mapeo, ¿cómo se vinculan los dos extremos de una asociación bidireccional?, ¿qué pasa si no se hace?
- ==Mediante la anotación @ManyToMany(mappedBy=“x”). Si no se usase se interpretaría como dos asociaciones unidireccionales separadas==
- ¿Es correcta esta consulta?
select i.workOrders.vehicle.client
from Invoice i
where i.date = '12/12/2014' --no porque el formato de la fecha no es válido- Describe a grandes rasgos la arquitectura hexagonal
- ==Lógica en las clases de dominio (la fundamental)
- ==Servicios en paquete application (transactions scripts se transforman en comandos)
- El mapeador hace persistencia (consultas externalizadas en orm.xml)
- Los clientes con saldo en sus bonos (CarWorkshop)
select v.client
from Voucher v
where v.available > 0- El último número de factura generado (CarWorkshop)
select max(i.number)
from Invoice i- La cantidad de órdenes de trabajo en las que trabajó un mecánico entre dos fechas (CarWorkshop)
select count(i.workOrders)
from Intervention i
where i.mechanic.dni = ?1 and i.workOrder.date >= ?1 and i.workOrder.date <= ?2- ¿Cuántas órdenes de trabajo tiene asignadas cada mecánico? Proyecta el id del mecánico y la cantidad. (Nota: los mecánicos tienen asignadas las órdenes de trabajo del día; una vez terminada la orden de trabajo ya no tiene mecánico asignado) (CarWorkshop)
select i.mechanic.dni, count(i.workOrders)
from Intervention i
group by i.mechanic.dni- Todas las órdenes de trabajo con tiempo total de intervención mayor de 4 horas (una orden de trabajo puede tener varias intervenciones) (CarWorkshop)
select w
from WorkOrder w
where w.id in (
select i.workorders.id
from Intervention i
group by i.workOrder.id
having sum(i.minutes) > 240
)Preguntas Recuperación de Información
- Definir consulta
- Es la traducción de una necesidad de información que permite al sistema recuperar el mayor número posible de resultados relevantes
- Ventajas stemming
- ==Stemming: Reducción de palabras a su raíz (que no a su lema)==
- Ej: universo, universidad, universitario, universitarias
- ==Ventajas:
- ==Reduce el número de términos que conforman el lenguaje de indexación
- Aglutina términos que están relacionados semánticamente
- ==Inconvenientes:
- ==Overstemming: términos no relacionados entre sí pueden reducirse al mismo stem==
- idf (inverse document frequency)
- A mayor número de documentos que contienen un término, menor es la importancia del mismo y viceversa.
- ¿Se puede hacer un estudio de la exhaustividad de una búsqueda en la web?
- No, se podría hacer en un entorno controlado donde ya sepamos cuánmtos documentos son relevantes de antemano. En la web, el número de resultados es prácticamente infinito, por lo que aunque retorne 10 documentos y los 10 sean relevantes, aunque la precisión sea del 100% no se sabe cuántos documentos relevantes existen realmente.
- Diferencias recuperación de información tradicional a en la web
- La recuperación en la web es muy distinta:
- ==La cantidad de documentos es muchísimo mayor
- ==Mucha mayor heterogeneidad
- ==Entorno adversarial
- ==Es preciso explotar la estructura de hiperenlaces
- Puede explotarse el comportamiento agregado de los usuarios
- Unidad de un sistema de recuperación. Puede ser un párrafo, una sección, un capítulo, una página web, un artículo o un libro completo.
- Documento
- Tarea de recuperación de información en la que el usuario especifica su necesidad de información a través de una consulta que inicia una búsqueda de documentos que probablemente son relevantes para el usuario
- ==Búsqueda ad hoc==
- El término de inverse document frequency fue propuesto en la década de…
- 1970
- Función de ranking para la asignación de relevancia a los documentos en un buscador basada en los modelos probabilísticos desarrollados por Stephen E. Robertson y Karen Spärk Jones.
- Okapi BM25
- Representación simplificada de documentos utilizada en recuperación de información donde se tiene en cuenta la frecuencia de aparición de las palabras pero no el orden de las mismas
- Índice
- Nombre del algoritmo que permite explotar la estructura de hiperenlaces para determinar el ranking de distintas páginas web en un buscador
- PageRank
- Búsqueda de recursos en una colección que son los más próximos (según una medida de similitud o disimilitud) a un objetivo dado
- Best-match retrieval
- Si estuvieras escribiendo sobre un tema y fueras a usar la información contenida en un documento dicho documento sería… relevante
- Sistema de software diseñado para ofrecer listas de documentos en la Web a partir de una consulta textual buscador web
- Estudio de sistemas automáticos que permitan a un usuario determinar la existencia o inexistencia de documentos relativos a una necesidad de información formulada habitualmente como una consulta. recuperación de información
- El primer sistema de recuperación de información fue descrito en la década de… 1950
- Técnica para reducir palabras a su raíz: estematización (stemming)
- Conjunto de los diferentes términos que aparecen en una colección de documentos: vocabulario
Preguntas NoSQL
- Explicar brevemente el teorema CAP
- El teorema CAP dice que en sistemas distribuidos es imposible garantizar a la vez: consistencia, disponibilidad y tolerancia a particiones:
- ==AP: garantizan disponibilidad y tolerancia a particiones, pero no consistencia de forma total
- ==CP: garantizan consistencia y tolerancia a particiones, pero sacrifican disponibilidad
- CA: garantizan consistencia y disponibilidad, pero tienen problemas con la tolerancia a particiones. Este problema se suele gestionar replicando los datos
- Modelos de datos NoSQL
- ==Clave-Valor
- ==Documental
- ==Almacenamiento en columnas
- Grafo
- Consistencia eventual
- Datos inconsistentes pasado un tiempo. Se permite inconsistencia en la replicación, pero eventualmente todos los nodos estarán actualizados
- Quorums
- Son el número de nodos en los que hay que escribir un dato antes de indicarle al cliente que su dato ya está grabado. Después de eso, los datos se siguen propagando por las distintas réplicas.
- ==En la lectura es el número de nodos que hay que contactar para leer un dato (y que devuelvan el mismo valor) antes de devolver al cliente el valor pedido.==
- ==En la escritura gana la escritura con la mayoría de nodos
- Consulta que devuelva películas que no tienen director
MATCH (m:Movie) WHERE NOT ((m)<-[:DIRECTED]-(:Person)) return m- ¿Además de las bases de datos en grafo, qué otros tipos de bases de datos se incluyen habitualmente dentro del grupo de sistemas NoSQL?
- Clave-Valor, Documental y Almacenamiento en columnas
- Describe brevemente qué son y cuál es el beneficio principal de los Quorum de lectura y escritura en un cluster de servidores
- ==De escritura W>N/2:
- ==Son el nº de nodos en los que hay que escribir un dato antes de indicarle al cliente que su dato ya está grabado. Después de eso, los datos se siguen propagando por las distintas réplicas.
- ==De lectura R:
- En la lectura es el nº de nodos que hay que contactar para leer un dato (y que devuelvan el mismo valor) antes de devolver al cliente el valor pedido.
- ¿Cuáles son las alternativas para la distribución de datos en una base de datos en un cluster de servidores?
- Replicación, fragmentación y servidor único
- ¿Cuáles de los siguientes son elementos principales del teorema CAP?
- Consistencia, Disponibilidad y Particionamiento
- Escribe una consulta en Cypher que devuelva los actores de las películas en las que no dirige “Clint Eastwood”
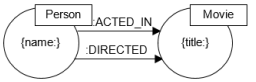
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE NOT (p2:Person {name: "Clint Eastwood"})-[r2:DIRECTED]->(m)
RETURN p.name- Escribe una consulta en Cypher que devuelva los actores que actúan en una película cuyo director también actúa en la misma
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(dir:Person)
WHERE (dir:Person)-[:ACTED_IN]->(m)
RETURN p- Escribe una consulta en Cypher que devuelva los directores que actúan en una película que ellos mismos han dirigido
MATCH (dir:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(dir)
RETURN dir- Resume al menos dos inconvenientes que se señalan habitualmente como típicos de las bases de datos NoSQL
- ==Están menos maduras que las relacionales
- ==Tienen funcionalidad limitada:
- ==No tienen control de seguridad
- ==No tienen control de integridad
- Atomicidad elemental sin transacciones o transacciones de bajo nivel
- Escribe una consulta en Cypher que devuelva la película que más actores tiene
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE m, count(*) as counter
ORDER BY counter DESC
RETURN m